
Software has eaten the world mainly because of the incredible success of Web 2.0 platforms. Recently, platforms have been the most successful and also surprisingly diverse businesses dominating many industries including retail (Amazon, Alibaba), advertising (Google, Facebook), video games (Epic/Unreal, Valve/Steam), mobile software (Apple), communication (Tencent), movies (Netflix), travel/hospitality (Booking.com, Airbnb), mobility (Lyft, Uber), restaurants (DoorDash) and even second-hand sneakers (Goat)! There has to be a platform for anything by now, right?
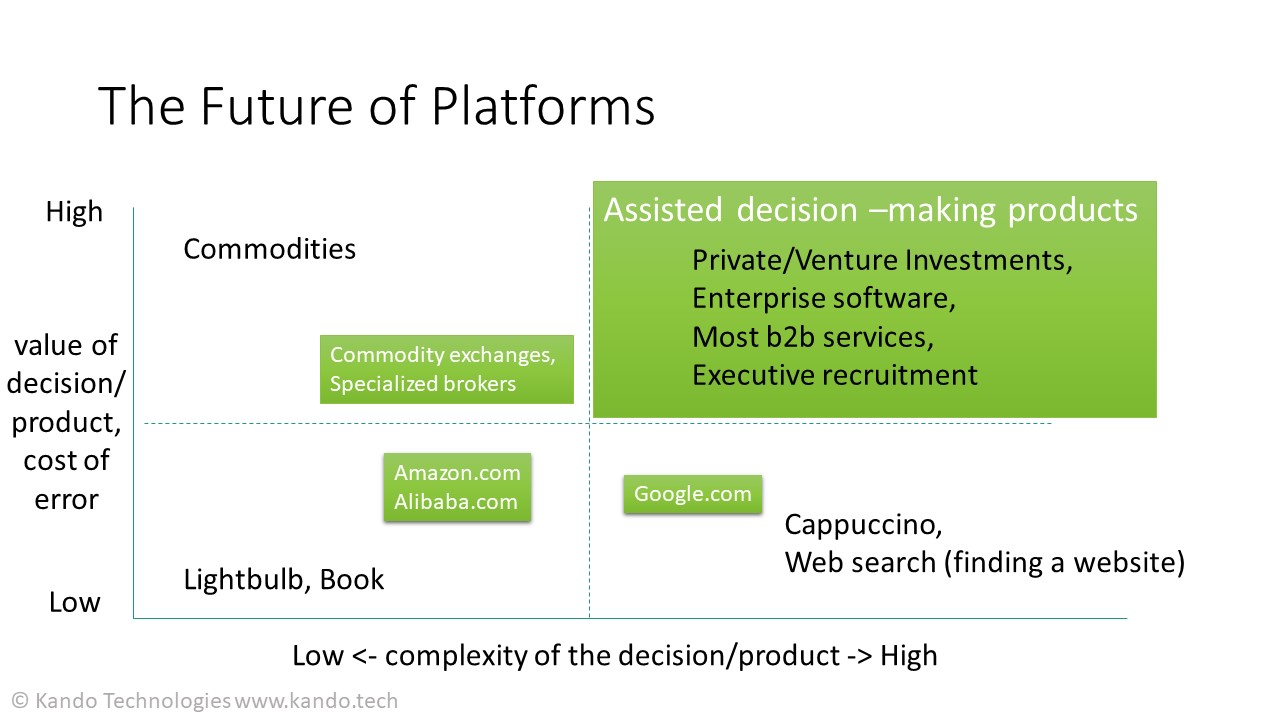
Well, almost. There are no platforms for (new) luxury goods and services or for complex business transactions like business finance, private investments or enterprise software. Luxury brands are obvious: part of the value prop comes from high differentiation and a strong brand image. It makes no sense for Hermes to spend all this money on marketing and then offer Birkin bags on Amazon. But what about the b2b/enterprise space? This is not for the lack of trying — enterprise or B2B platforms have been “the next big thing in the making” that VCs have been expecting since 2017, maybe even earlier.
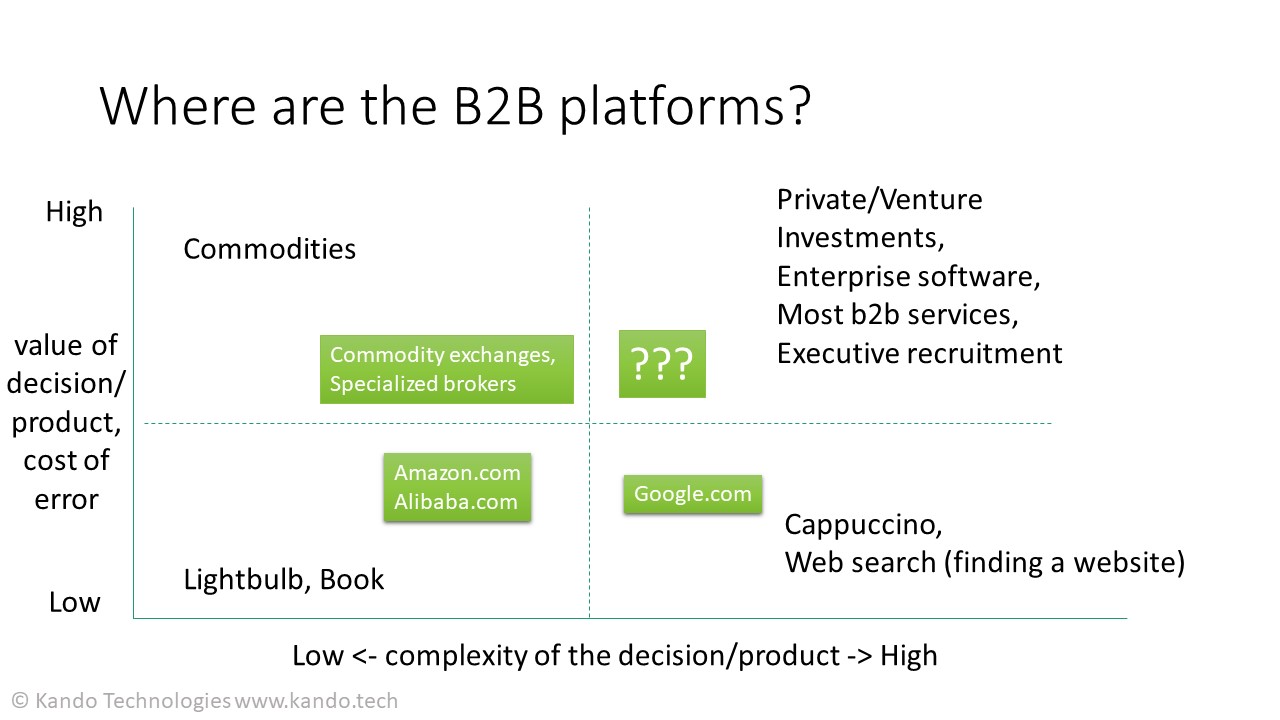
To answer this question, let’s start with… decision making! How do we, as individuals or companies, make decisions and why do we make decisions are fascinating questions. It’s definitely outside of the scope of this article. What is important here, is that in every decision there’s some input data involved. There is some kind of a decision making “engine”/black box inside people’s brains or consciousness that makes decisions based on internal (memory, company record) and external data. Data input -> Decision engine -> Decision.
This means that data input is very important because different data will result in a different decision generated by the same decision engine. It’s also important to recognize that the human body alone sends 11 million bits per second to the brain for processing and we live in a world that generates 2.5 quintillion bytes of data each day (and accelerating). At the same time, the conscious mind seems to be able to process only 50 bits per second. It’s impossible to consciously process all the available data, either as an individual or a company, so some sort of compression and selection mechanism is needed. With no formal selection or curation process, we use shortcuts or biases to reduce the amount of data to process. Contextual data is often used for curation (formally or as unconscious biases). For example, provenance, who published, is as important as what they published. Another very important selection mechanism is reputation, a record of historic interactions and outcomes associated with the data source (a promise made by a stranger has a different weight than a promise made by a lifelong friend). Interestingly, humans can keep track of about 100–150 people we interact with, which is also the maximum number of people in a tribal society, with no organized structure. At the same time, we can potentially directly interact with 4.4 billion internet users.
Web 1.0 -> 2.0
Internet adoption created a huge amount of new, user-generated data/content (Web 1.0). The Internet tech stack didn’t include tools for curating the data or establishing a consensus about the data (like the audited financial statement in the analogue world). The Internet didn’t come with tools to handle extremely important contextual data, identity and reputation, either. The closest early proxy for reputation would be Google page rank, which could explain why Google search became so relevant and popular. Web 1.0 no link between the existing analogue infrastructure (gov. issued documents, audited financial statements) and the digital world either. To fill this void, data curation, identity/provenance, reputation and also value transfer were bundled together and handled by the emerging private platforms like Amazon, Apple, Facebook, Google, Uber, Airbnb, and others. This is how Web 2.0 emerged. This bundle created the secret sauce of the platform business: trust provided to all participants. Strangers don’t have to trust each but they can trust the platform.
Web 2.0 platforms were so successful because they solved the most important Web 1.0 problems related to data processing and value transfer. They provide incredible benefits for their participants, manly reduce the cost and risks of the decision-making process by 1) reducing the amount and complexity of data that needs to be processed by users; 2) providing consensus about data, standards and interoperability inside the platforms; 3) handling identity and reputation, 4) recently, starting to provide recommendations and even more curation by applying AI/ML
Successful doesn’t mean perfect. There are a number of issues with the dominating platforms and marketplaces, most of which are natural consequences of platform architecture, both in terms of technology and business models.
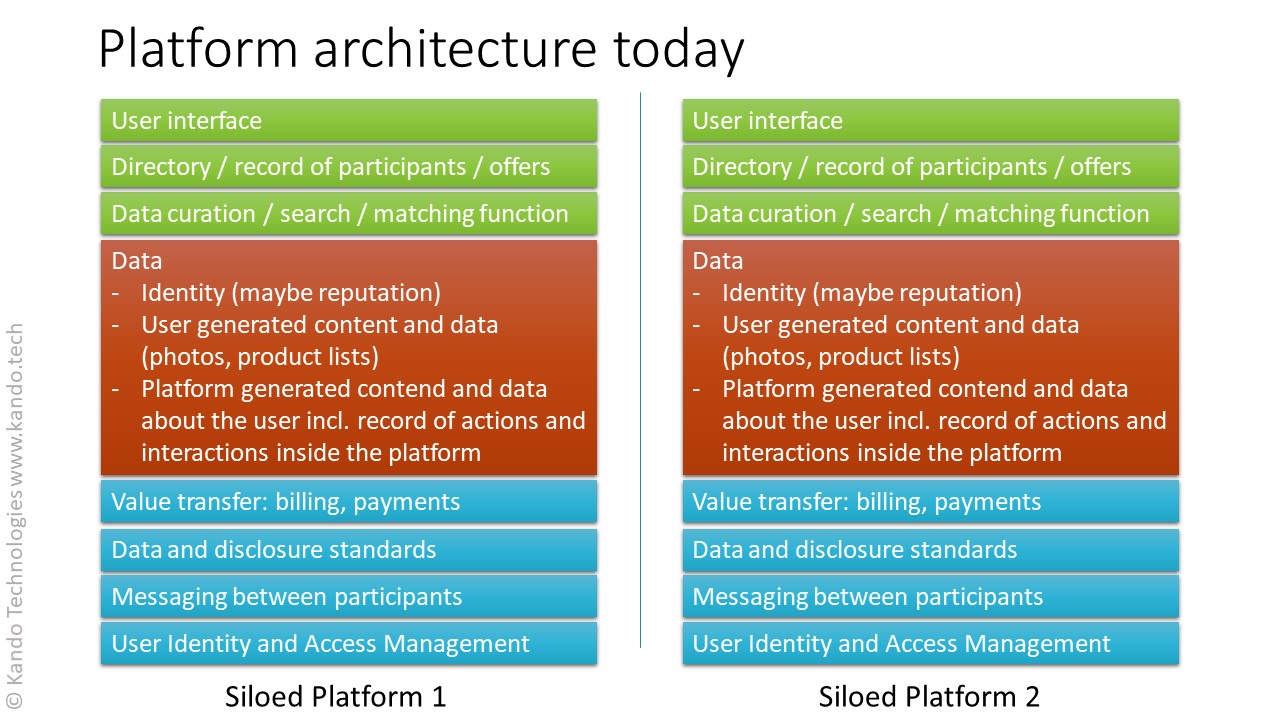
On the technology side, we have each platform operating a proprietary, siloed system with no links to other systems. Every provider has its own identity and access management system (different login to each platform) collects its own data, sliced and diced differently just enough so they are not interoperable. If there are APIs available, they are incompatible and require custom connectors and another bigger silo that aggregates data. This means that users have no access to choices outside the platform. There might potentially be better options for them, but users will not be aware of this fact, since the platform can not see anything outside itself. Data access rights are a problem too. Users can’t tell who’s accessing their data and for what reason. A good example is the case of Amazon using marketplace merchants’ data to launch its own competing products. Finally, since the entire platform is an opaque black box for the users, the curation mechanism is also opaque. Users don’t know how the recommendation/matching algos work.
The problems with the dominant business model start with misaligned incentives. Recommendations and matches, any data really, can be skewed to maximise platform monetization. For example, the biggest advertisers or items generating bigger commissions can be ranked higher. Next, there is the vendor lock-in. If all my data is stored by the platform or all my business comes from it, switching costs and risks are very high. Finally, there’s the problem with the power-law distribution of success, or simply put, the winner takes all as far as platforms go. The winning platform is not only the dominant or biggest platform, but it’s the only player in the market, a de-facto monopoly, much more powerful than the platform users, that can extract enormous value from the participants (30% fees in the Apple app store, 50%+ merchant fees on Amazon marketplace).
This is exactly why there are no serious B2B platforms yet: No business will hand over their data and key decision-making processes to a third-party monopoly to be reduced to the role of commoditized “Uber drivers”.
Unbundling
For high value, complex B2B transactions marketplaces and platforms to exist, the following needs to be true:
- Companies need to be able to control their data: the way it’s stored, accessed and shared with others.
- There needs to be a consensus mechanism in place to ensure shared data can be trusted.
- Identity and persistent reputation need to be portable and controlled by companies and individuals (not monopolies).
- Companies and individuals need to operate based on shared standards and protocols in an open, interoperable environment.
Under these conditions, platforms become assisted decision-making and/or matchmaking products. They act as a lightweight client that contains an index of participants, data and AI/ML algorithms. Enterprise platforms can only be successful and highly customizable environments and toolkits that companies can use to build their own, bespoke decision-making products using available widgets and APIs.
What needs to happen is the unbundling of platforms, both in terms of their technical architecture and business/monetization models.
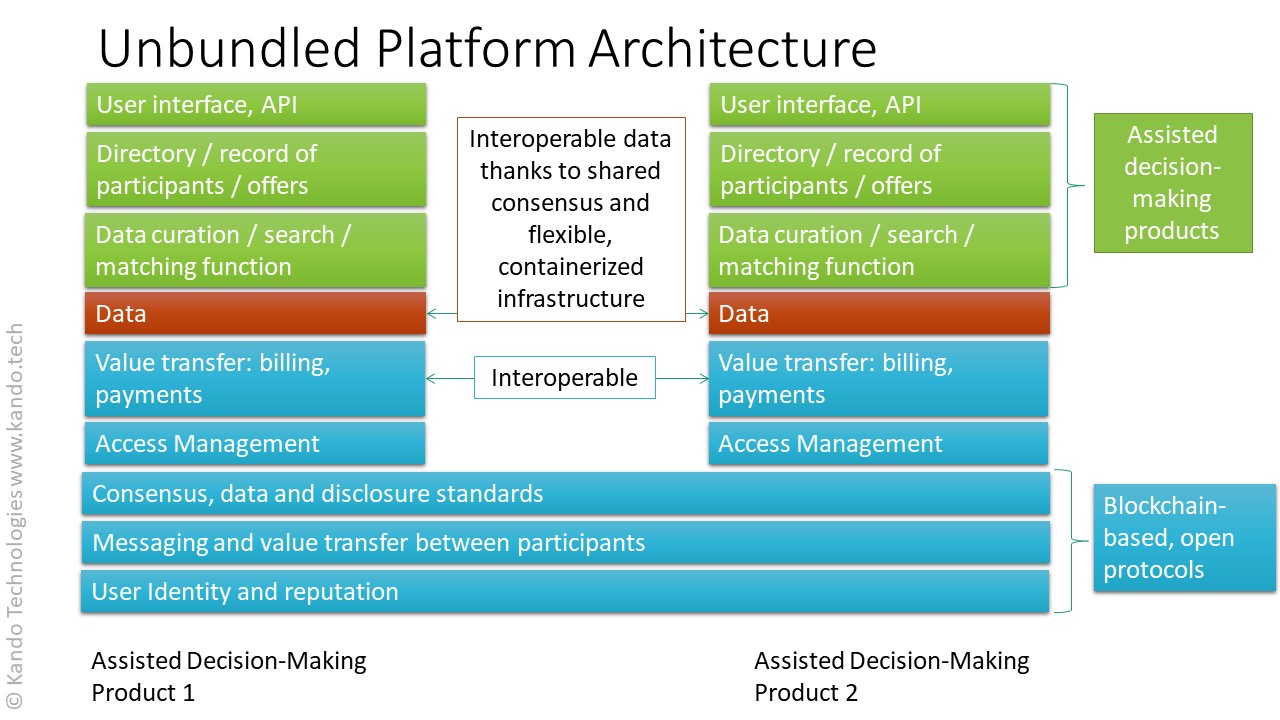
The foundation of the unbundled architecture consists of open protocols and standards for resolving identities and therefore reputation in an open ecosystem. Once we have solutions for identity, secure messaging and value transfer are also possible. Finally, there needs to be a decentralized mechanism to establish consensus about data of other ecosystem participants (an equivalent of auditing and certification in the analogue world). All of this needs to happen in a way preventing a single company from controlling identity, reputation and data consensus inside its proprietary silo. These have to be hosted in a transparent and decentralized way (similar to DNS). Otherwise, another bigger monopoly will emerge and no one will participate in the ecosystem.
At the moment blockchain technology is the best bet in terms of solving for all of the above requirements. It enables this in a cost and energy-efficient, tamper-proof and auditable way.
Modern commercial-grade blockchains are compliant, secure, reliable and operate at very high, commercial-grade speeds. They allow for launching a publicly-accessible network (for the general public and end-users) with permissioned, decentralized consortium of vetted validators (including businesses, regulators, developers, professional node operators).
The next, middle layer of the ecosystem consists of back-end, professional B2B solutions built on top of the protocol layer. These solutions include services, toolkits, libraries, SDKs, platforms that handle access management, value transfer (including billing and payments) and data management and storage. They are used by the specific top layer applications.
Finally, at the top, there are many lightweight front-end, user-facing applications. Due to the nature of the performed tasks, these are the new breed of assisted decision-making products. They generally provide some kind of data curation/matching, a directory/index of participating users and a user interface for humans and/or other machines (APIs).
These applications can resemble today’s platform in terms of user experience for low value and/or complexity products and situations (say matching customers with local restaurants), but they will be built using the open architecture so that users can opt-out of using selected services in a platform bundle and decide to build their own client apps instead (say someone with very specific dietary requirements and schedule can design an app that picks the best restaurant offers just for them).
On the enterprise end of the spectrum, most of the activities happen in-house, but enterprises have a secure, trusted and, at the same time, open environment to efficiently interact with each other and a large volume of smaller businesses.
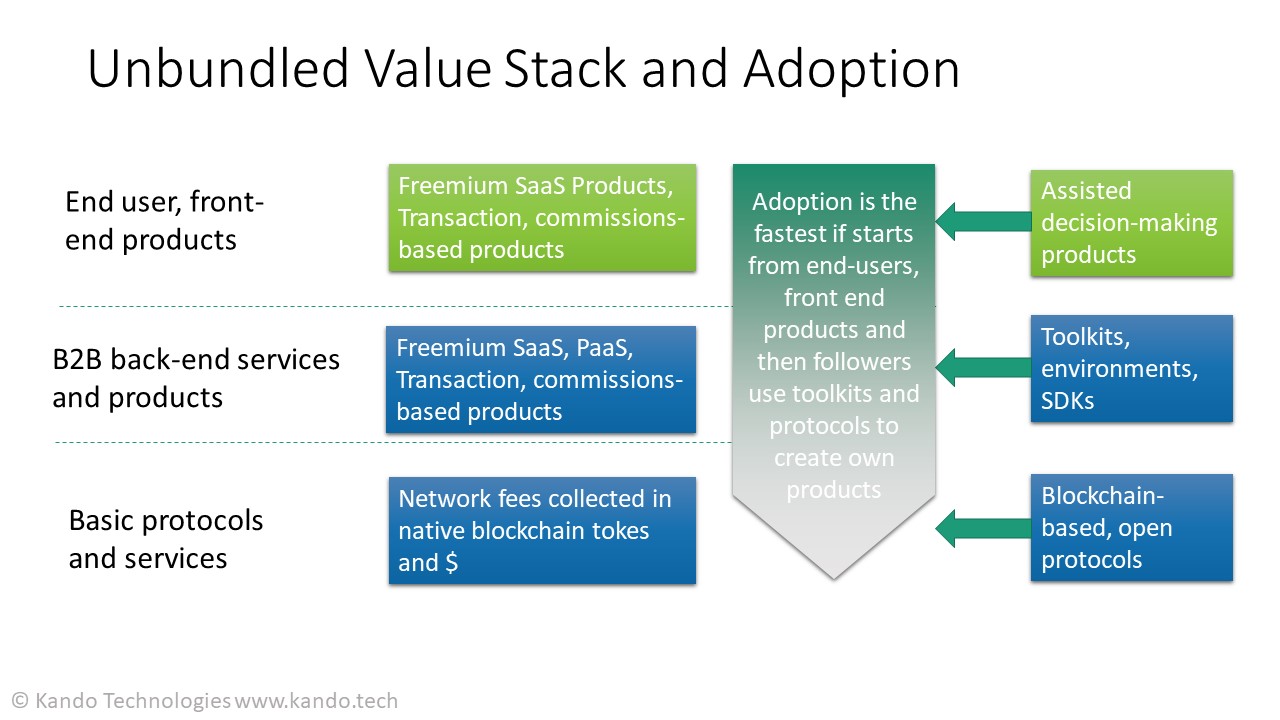
The business playbook is also transformed. Rather than a monopolistic operator offering a one size fits all bundle, the new ecosystem has many specialized players that can co-exist offering different parts of the value stack.
On the top of the stack, the front-end, end user-focused assisted decision-making applications will be offered as SaaS or developed (partially) in-house. There is also a new category of services that charge some sort of success fees/commissions. This is possible thanks to the data consensus established in the ecosystem, so there is verified billing data available. In the middle layer, we can find B2B, back-end products used by the front-end solutions in the top layer. These are monetized through both subscription and transaction fees. Finally, at the bottom layer, there are network fees collected by the blockchain networks. In order to facilitate adaptations these fees are collected in both national, fiat currencies ($, €, £, …) and native tokens of the networks (similar to gas fees on the Ethereum blockchain, for example).
Users have always been and will be attracted by the value prop of the product they are using, not the technology or features. Therefore, bootstrapping these ecosystems should happen from the top of the value stack in order to be most successful. Companies can offer B2B marketplaces with the added benefits of the unbundled stack to end users and then can offer middle and bottom layer solutions to other ecosystem participants — followers building their own assisted decision-making products.
Implications
From the technology perspective, unbundled platforms with robust data sharing and management solutions will greatly accelerate the adoption and deployment of AI/ML, which then can be present everywhere. It will be a fundamental architecture premise, not a feature. Just like the Internet. There will be no “AI” button in a product — the entire product will be designed with AI architecture in mind. Consequently, every company will be an “AI company”, just like every company is an “Internet company”. Therefore, companies will need development platforms, environments, toolkits, SDKs and widgets to develop their own AI solutions.
From the user experience perspective, unbundled platforms enable users (both individuals and companies) to run their own AI/ML modules having access to their own private information and data shared by third parties.
Fundamental changes will happen to the way we do business in general. First, reputation and relevance will become more important than marketing and advertising, as they become very important features in every AI/ML recommendation/matching products. Second, transaction costs will be drastically reduced in the entire economy. These include direct costs of interacting and conducting transactions, thanks to automation but also indirect costs and risks associated with a lack of data for making the best decisions. This means, for example, that bespoke B2B financial products can be offered at a cost of commodity products.
To close the discussion, here’s a practical recommendation, as in “what does this mean for my business”: We’ve agreed that AI will take over many business decisions, and most of the B2B discovery in the future (i.e. private fundraising, B2B sales intelligence, supply chain and talent discovery) is going to be automated, and one of the factors of success for future business will be the reputation that ranks you higher in the discovery process. So the big moonshot would be to build a universal automated business discovery platform, where each business maintains an identity around which they build such a reputation, but ultimately use for all transacting with other businesses. Which BTW, means creating a more efficient, global business environment that facilities innovation and provides unbiased access to opportunities for everyone. We are looking with excitement at such a future.

I’m the Chief Operating Officer at Kando. You can connect with me on Twitter and LinkedIn.